Millions of HelloFresh customers visit My Deliveries weekly to select their upcoming meals and add-ons. Unfortunately, it also receives a lot of complaints, mainly related to loading issues. This article is about how I led a multi-team, cross-functional initiative to replace its most painful pain point to improve the user experience and alleviate the stress on our systems.
The following screenshot represents a typical My Deliveries screen. The most prominent elements are the navigation bar, the ribbon of weeks, and the menu for the selected week. Customers can select any number of meals and add-ons from the menu for their upcoming deliveries.
The following screenshot represents My Deliveries after it failed to load the menu. Loading failures were often caused by traffic spikes, for example, after a marketing campaign. The experience was unsatisfactory for our customers, and it was an off-putting first impression for newcomers.
Many requests are necessary to fetch the required data for this screen. On a decent connection, it takes 4 seconds to reach the step that fetches the menu, 8 seconds to load everything. Now, imagine on a mobile phone, on your way back from work.

Serving menus in 2019
Back in 2019, the API monolith was serving menus. Aggregating the pieces constituting a menu was not a simple thing. The code base was large and difficult to understand and maintain. And although we had a service for meals, the API monolith was still reading them from a shared database. Any change to the "meals" service had to be reflected in the API monolith, which was a common source of errors.
Fetching the menu would fail if any of its components failed. For example, you would get a sad egg if there was an issue getting the ratings for the meals. And because the API monolith is a PHP application, all tasks were sequential.

The numbers indicate a sequence of tasks, none run in parallel
The API monolith spent a quarter of its time serving menus. On regular days, that meant ~40 out of its ~150 pods were occupied serving menus. After a marketing campaign, even with auto-scaling, sometimes there weren't enough resources to support the burst of traffic.
The "menu" endpoint was only used by My Deliveries but its response was not optimized for it. For instance, the response was a collection with a single item. The menu exposed many unnecessary properties, some obsolete, many null. The menu was leaving a lot of processing to the frontends, such as computing meal charges and formatting labels.
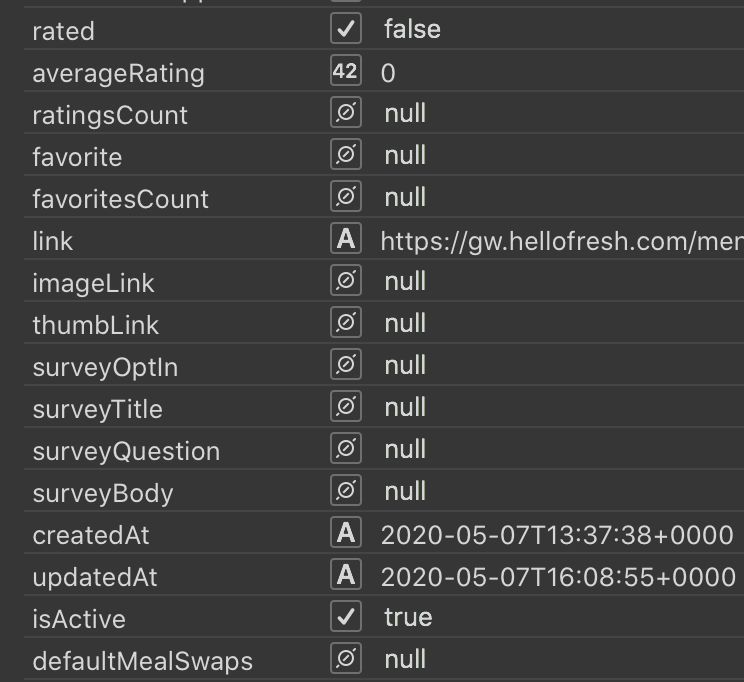
null values and unnecessary propertiesI'd summarize the shortcomings of the design as follows:
- The menu was expensive to produce and the result was messy
- There was no graceful degradation: a piece failed, the whole menu failed
- The API monolith is supposedly frozen, new features are verboten
- The API monolith is challenging to maintain and debug
- The API monolith is already using ~150 pods, scaling is not a solution
- The API monolith is costly to run
- The API monolith takes an hour to deploy (at best)
- Incidents related to traffic spikes
Introducing My Deliveries BFF
There had been a previous attempt to overhaul My Deliveries but, after two years of effort, the team couldn't make it to production, and the project was shutdown. Instead of a daunting overhaul, I got the idea to focus on a specific pain point, and you guessed it, that was the "menu" endpoint. I previously led an initiative to have smaller menus that reduced the menu size by 40 and the endpoint latency by 3. However, if I wanted a significant and durable improvement, I had to replace the "menu" endpoint and get the API monolith out of the picture.
With that in mind, I made a proposal to create a backend for frontend (BFF), detailing the services that would be re-used and the features that would need to be extracted from the API monolith. I made a list of the attributes sent to the upstream services to figure out what could be optimized if not removed. Regular deliveries were paramount to me. I made sure to have clear and detailed rollout phases. I wanted the BFF to steadily provide value during its development and get frontend integration started as soon as possible.
I set the following goals for the new design:
- Provide a great API for our frontends
- Speedup delivery of new features
- Support graceful degradation
- Fast deployments
- Easy to scale up
- Remove the API monolith from the picture
- Lower the number of downtimes and incidents
- Improve customer experience on all platforms
Provide a great API for our frontends
At HelloFresh, few services were providing accurate documentation for their API. Some were generating OpenAPI specs from their code, but the result was unpleasant. Users of these APIs were writing their own clients by hand, which, of course, would get out of sync in time. For the BFF, I wanted to try something new, write the spec first. If I wanted to get buy-in on this and make sure it is helping, I would have to use it too.
I worked closely with the frontend engineers on the OpenAPI spec for the BFF, and I guided a few of them to generate their clients instead of writing them by hand. On my side, I generated the server code from the spec, just like they did their clients. We saved a lot of human time going spec-first, especially because the iterative process required frequent updates. With a command line, the server code and the clients were updated automatically in seconds.
For the BFF's menu schema, we really went back to the drawing board, questioning every aspect of the previous schema or the approved design document I wrote. Nothing was off the table. I had two goals. First, I wanted the tiniest payload possible. Second, I wanted to move as much logic as possible from the frontend to the backend, so we would have only one code base to maintain instead of three. That is because the cost of updating the backend is nothing compared to the whole process of releasing mobile app updates. In the end, we managed to halve the size of the menu while preserving all its features. We even add some of our own, such as ready-to-display meal surcharges.
The following screenshot illustrates a BFF menu, its root and how it looks expanded.
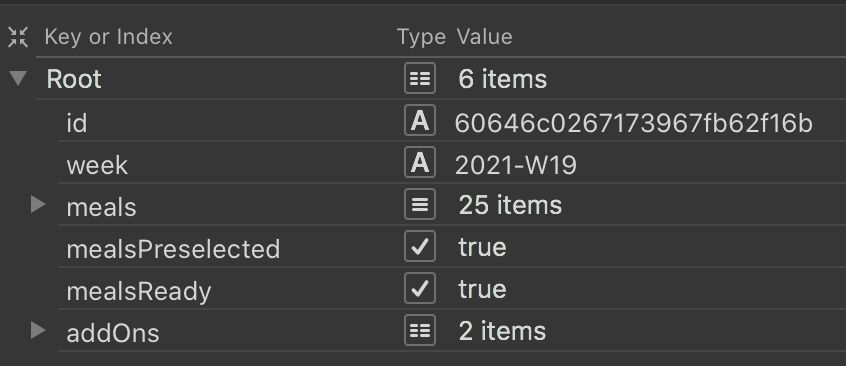
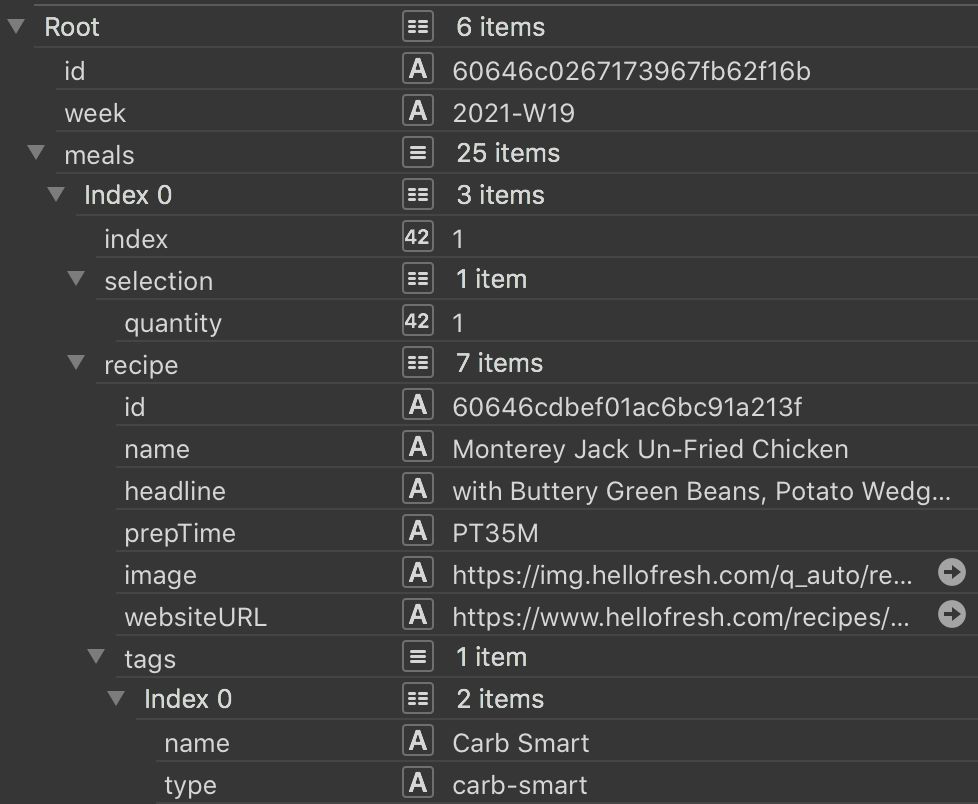
Graceful degradation
As a HelloFresh customer myself, there is nothing more annoying than going to My Deliveries to select upcoming meals only to be greeted by a sad egg. For the new design, I wanted to be able to select my meals even if ratings failed. The BFF would consider a request a success if it could provide meals and charges for premium ones. Anything else would be secondary. The response would include error fields to indicate missing components. Frontend applications would display whatever is available in the response and retry in the background. If possible, the screen would refresh with additional elements, or the applications would alert the customer.
The following example demonstrates how error fields can look. The origin is an enum that frontends can use to pinpoint the origin of an error and react accordingly. The reason wouldn't be displayed to the customer but could help debug.
{
"errors": [
{
"origin": "meals.ratings",
"reason": "the feedback service is down"
}
]
}Fast is good, reliable is better.
A multi-team, cross-functional endeavor
Replacing the "menu" endpoint was an endeavor spanning multiple teams and multiple disciplines. Planning, progress report, communication, and regular deliveries were challenges.
Six teams were involved in the project. Each already with their own roadmaps. To make sure deliveries were steady, we met every week to review the roadmap progress and discuss any blockers or delays.
I set up a root document in Confluence where anyone could get familiar with the project, track progress, and review proposals. To keep everyone in the loop, especially developers, I created short proposals for each change I was planning to make. That was a chance for me to get feedback, make adjustments, and build buy-in. For the participants, that was an opportunity to keep up with the project, review the changes, and propose amendments.
The following example is a proposal I made to move the logic that was in the three frontends to the backend. Instead of providing the data to compute and format a charge for a premium meal, which can be tricky depending on the number of servings and the premium type, the BFF would compute the charge and format the label. Frontend applications would only have to display values.
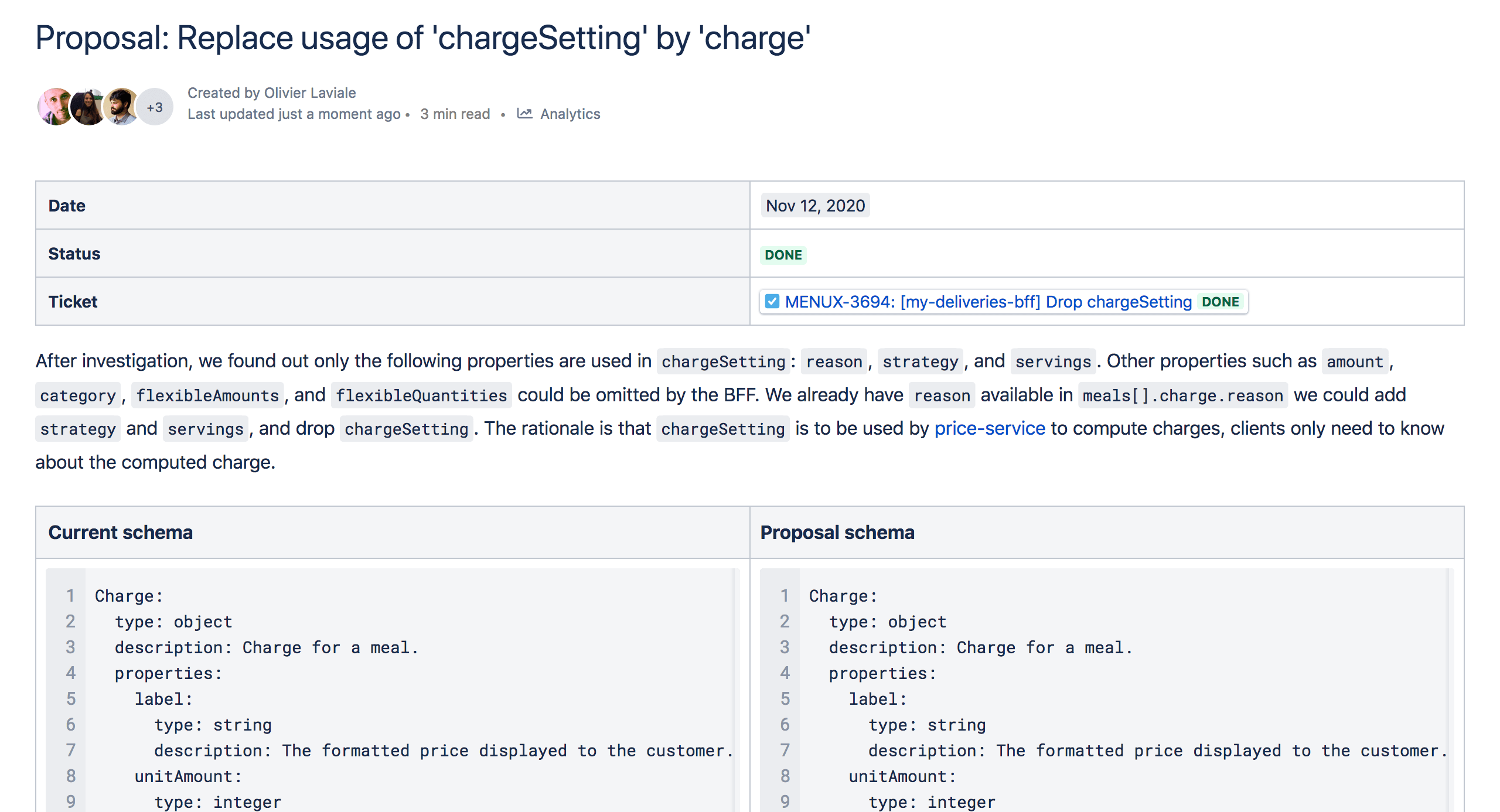
Also, to avoid overwhelming myself, I asked a few frontend engineers that demonstrated ownership qualities to become my champions. They were responsible for their discipline and were my preferred interlocutors. I remained in charge of the backend.
Serving menus in 2020
A year later, a lot has changed in the API monolith. It finally fetches meals from the "meal" service instead of reading them from the database. And we created a service for ratings and favorites. We updated the "add-ons" service to serve the list of add-ons, but the API monolith still fetched them from a shared database. We were close to releasing the BFF, so we decided to not waste effort on an update.

The numbers indicate a sequence of tasks, nothing runs in parallel
The BFF is serving menus as well now. The architecture is a little different there. First, we created a plugin for our new Gateway, that checks if a subscription identifier belongs to a customer. We don't have to use the API monolith for that or even deal with actual subscriptions. Second, we drastically reduced the number of entities to fetch. Gone are the subscription, the delivery items, and the product. Their information is already available in the frontend so the BFF gets them as parameters. Third, we wrote be BFF in Go, which allows performing tasks in parallel.
(Max Latency = Sum of all tasks)

The numbers indicate a sequence of tasks, many run in parallel
Results in numbers
We've been load testing the BFF regularly, and ahead of the big release, things were looking great. With a limit of 20 pods, the BFF could handle 5 times the normal traffic with little impact to the latency. That was also a tribute to the improvements we made to the upstream services.
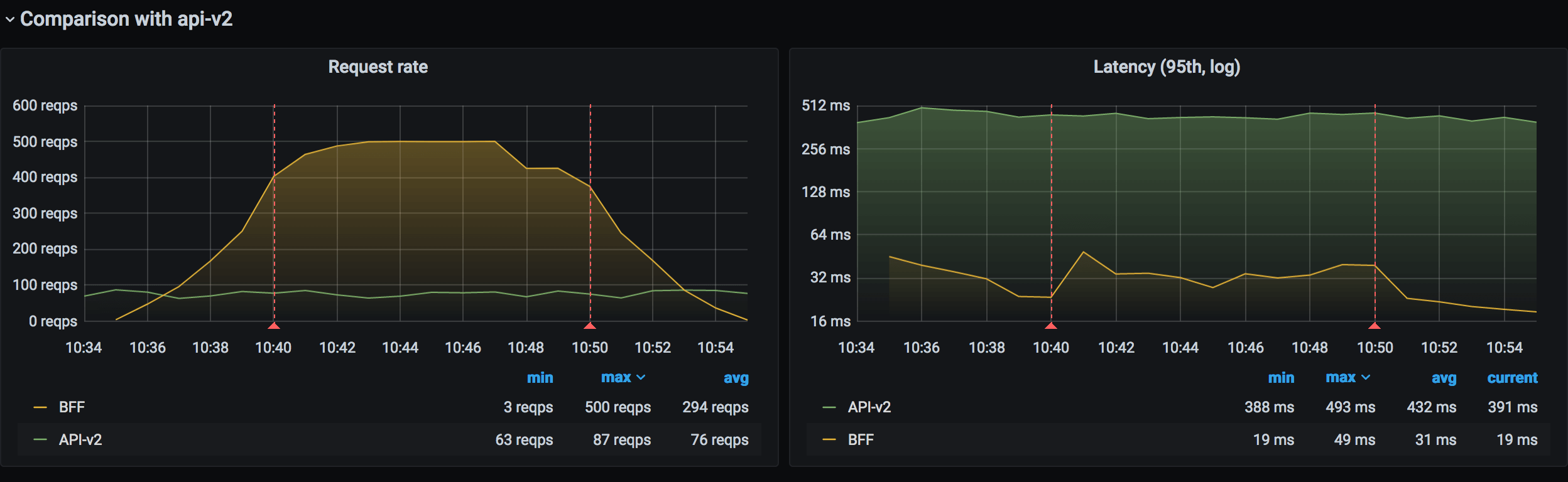
Once the BFF was complete, and frontend applications were ready to switch from the API monolith, it was time for the final stretch of tests. Using our experiment infrastructure, we slowly switched users towards the BFF until it was serving 25% of the traffic. We let it run for a week to compare the performance of the systems and monitor the feedback from our customers.
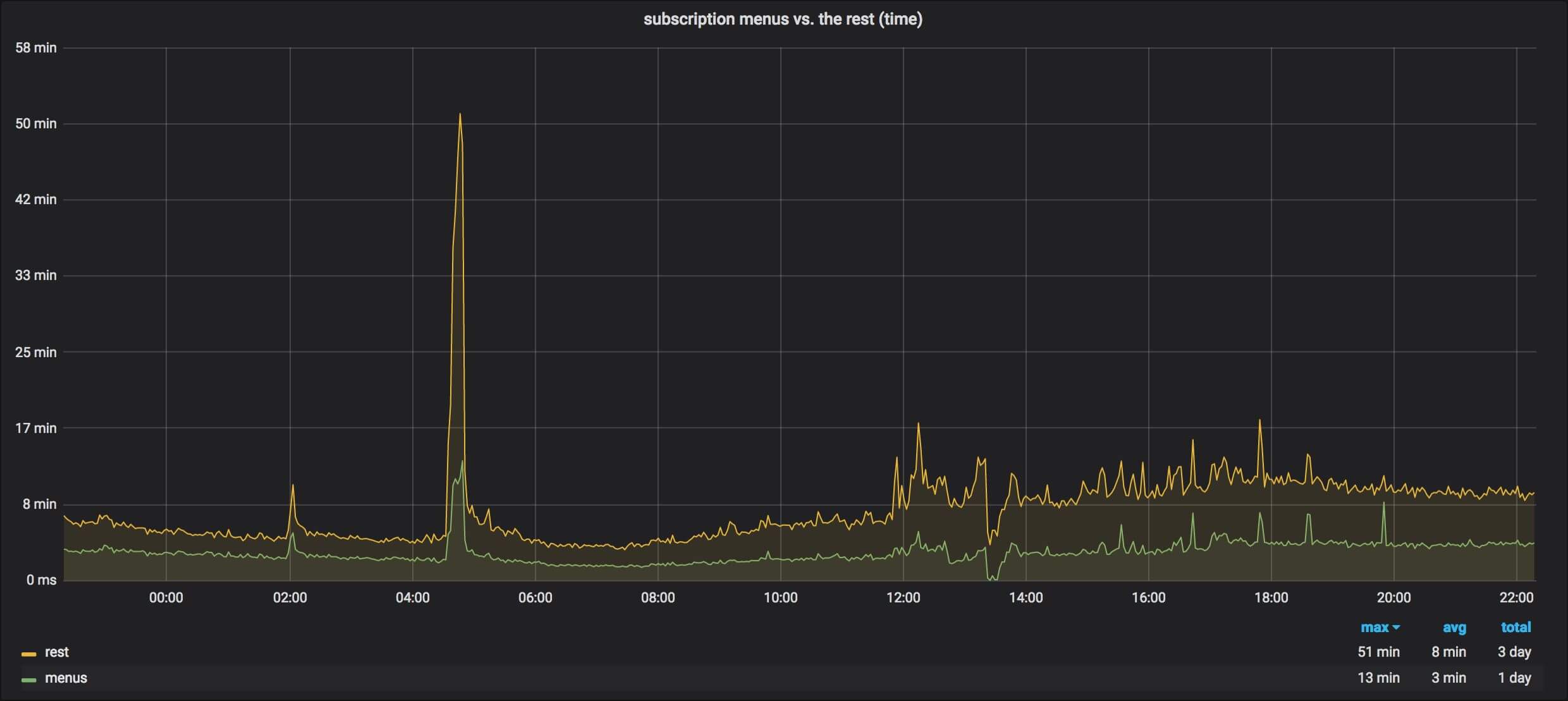
The following graph represents the percentage of the BFF's latency compared to the API monolith. If we consider P95, the BFF is able to serve a similar request in ~7% of the API monolith's time on average. In other words, the BFF is ~14 times faster than the monolith.
We also noticed a reduction in traffic to upstream services. For example, the "meals" service went from ~1000 RPS (request per second) to ~800 RPS. We weren't expecting a dip. The API monolith was doing more requests to the service than we realized—one would say unnecessary requests. You can easily notice the dip around 16H when the traffic-switch completed.
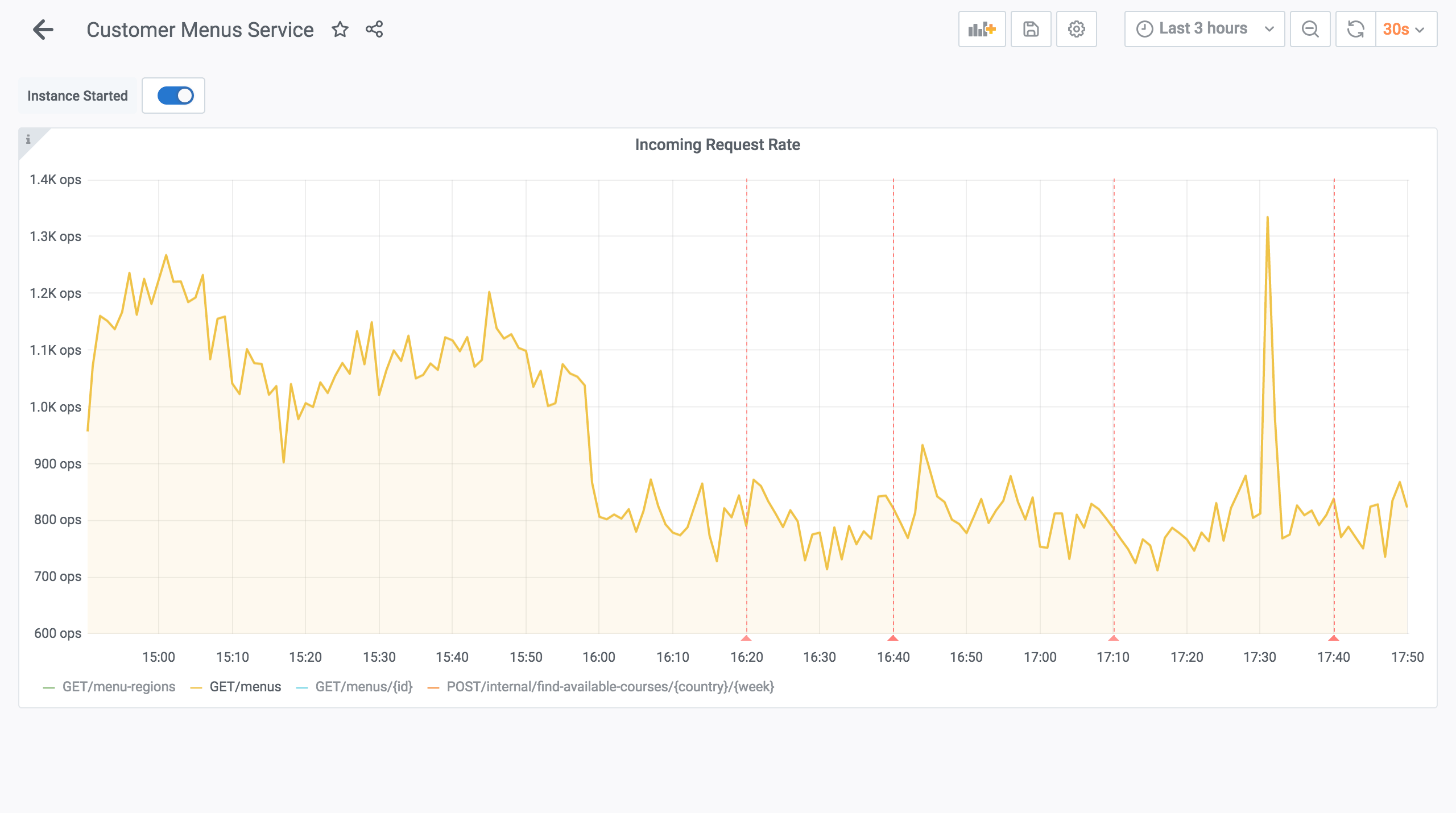
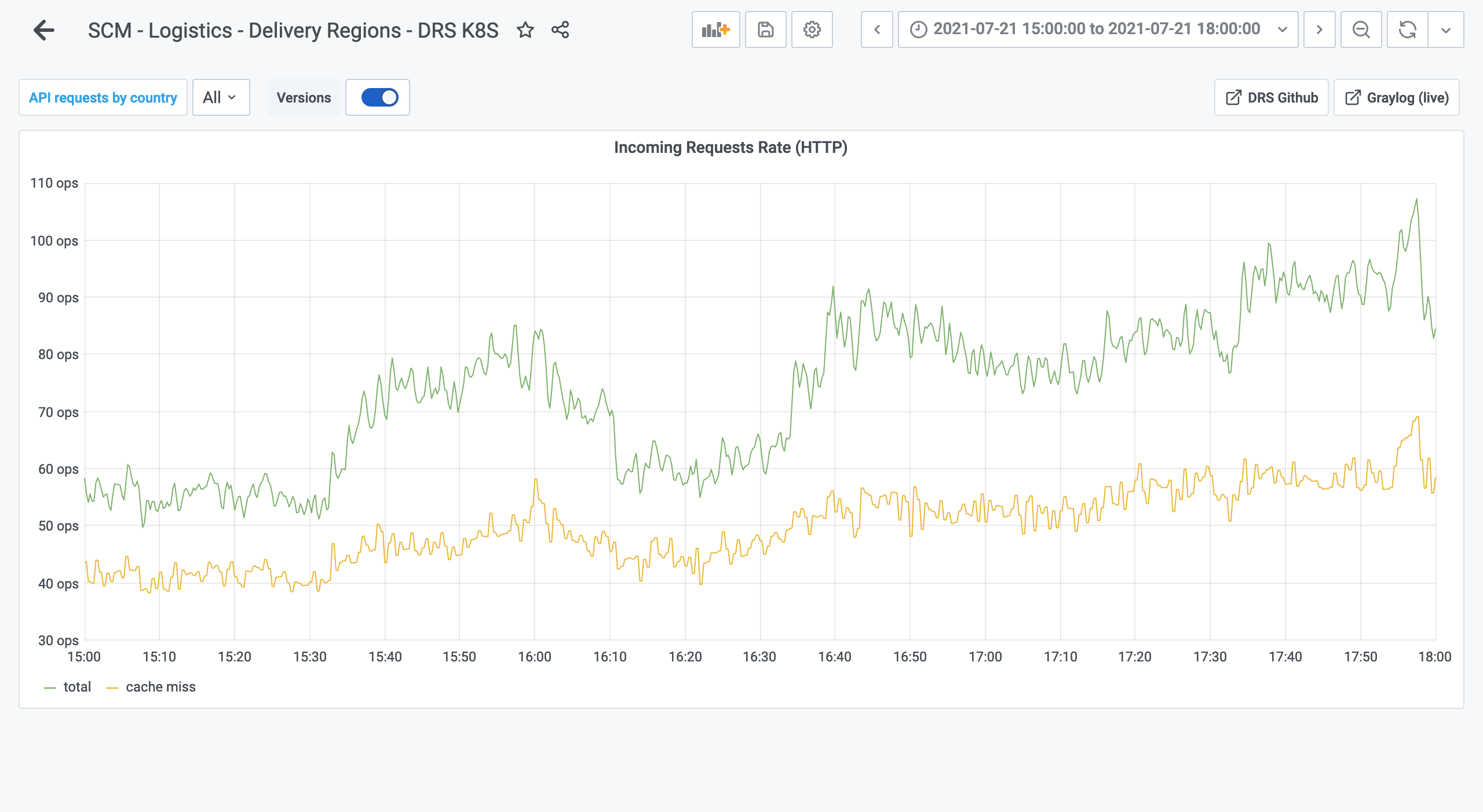
We noticed a similar reduction for the "logistic" service where the traffic went from 400 RPS to 200 RPS. Contrary to the API monolith, the BFF doesn't query the service because it gets the relevant information from the frontend as query parameters.
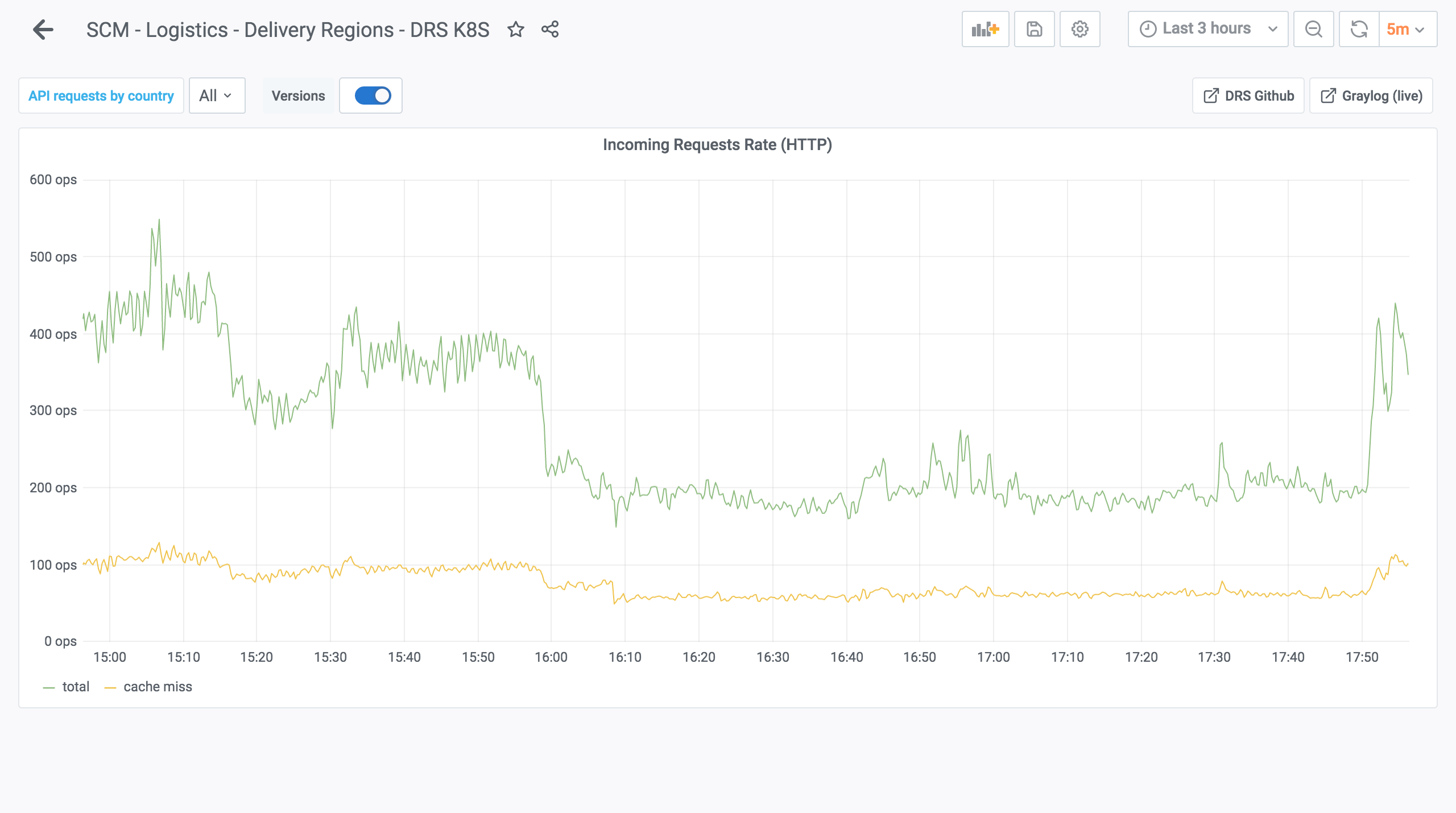
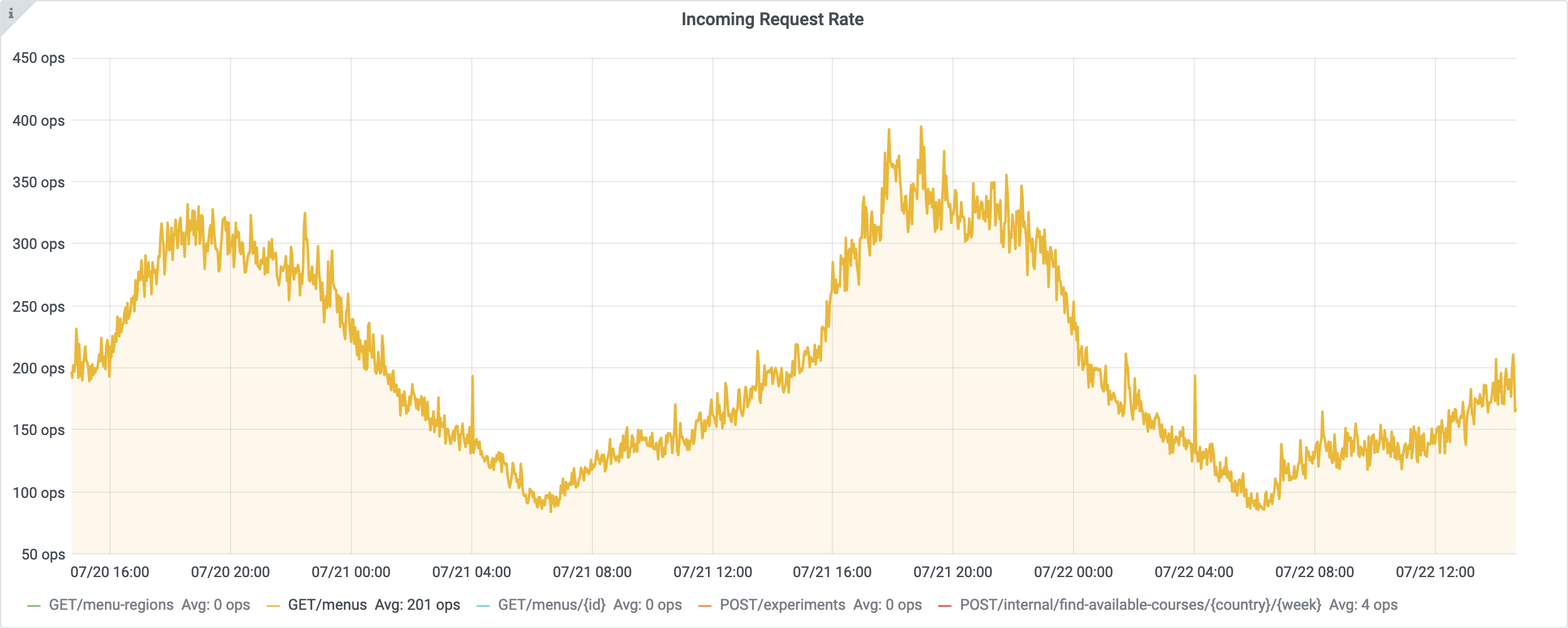
A month later, the switch to the BFF was complete. The reduction in traffic to the upstream services was even more impressive. For the "meal" service, the traffic went from a maximum of 1300 RPS to 400 RPS:
For the "logistic" service, the average went from 400 RPS to 80 RPS:
Spin-off projects
As if all of this wasn't enough, during the development of the BFF, we also launched spin-off projects. The first was an endpoint for the home screen of the mobile applications, that helped reduce the startup time by 35%.
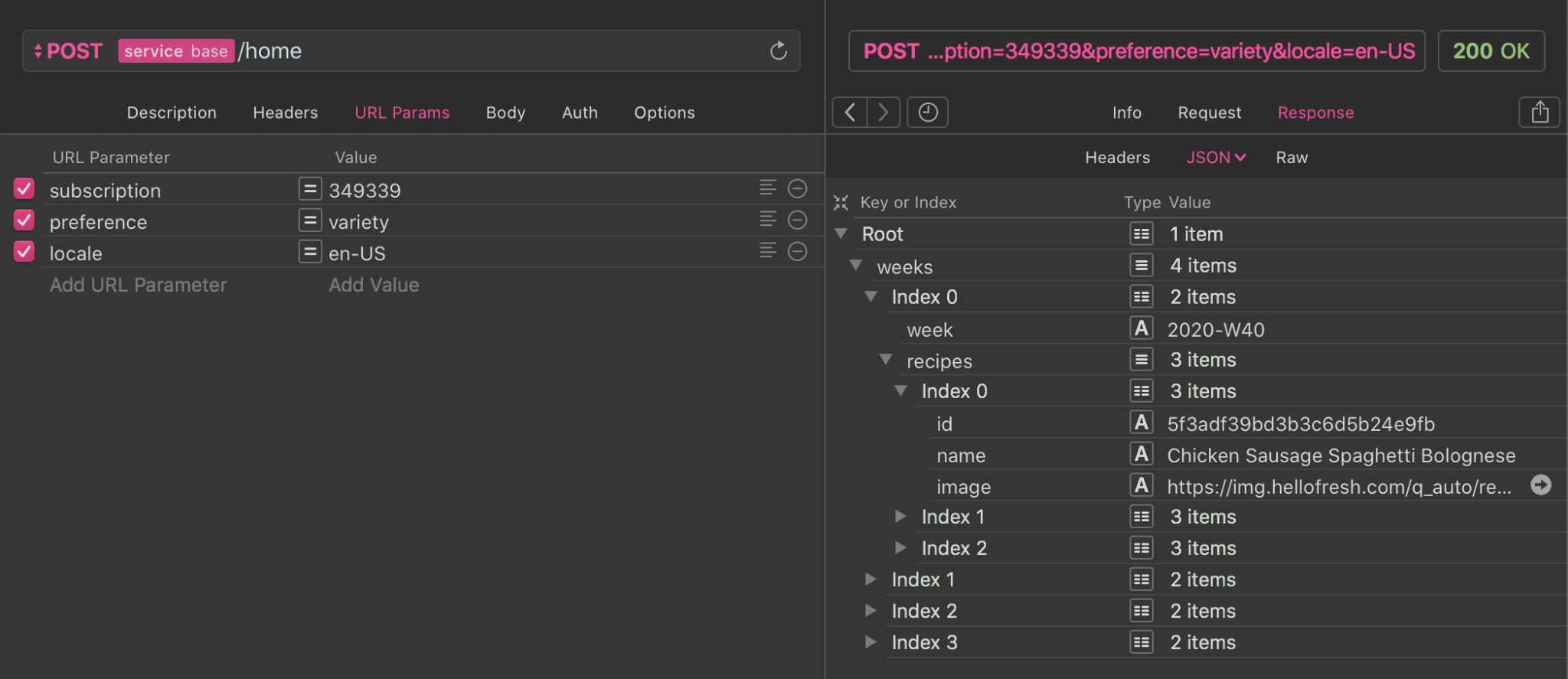
/home endpointThe second project was to separate My Deliveries in two screens: one for the upcoming deliveries, the other for the past deliveries. The Past Deliveries screen would feature the meals and add-ons previously selected by the customer. They would be arranged conveniently for customers to favorite, rate, and comment them.
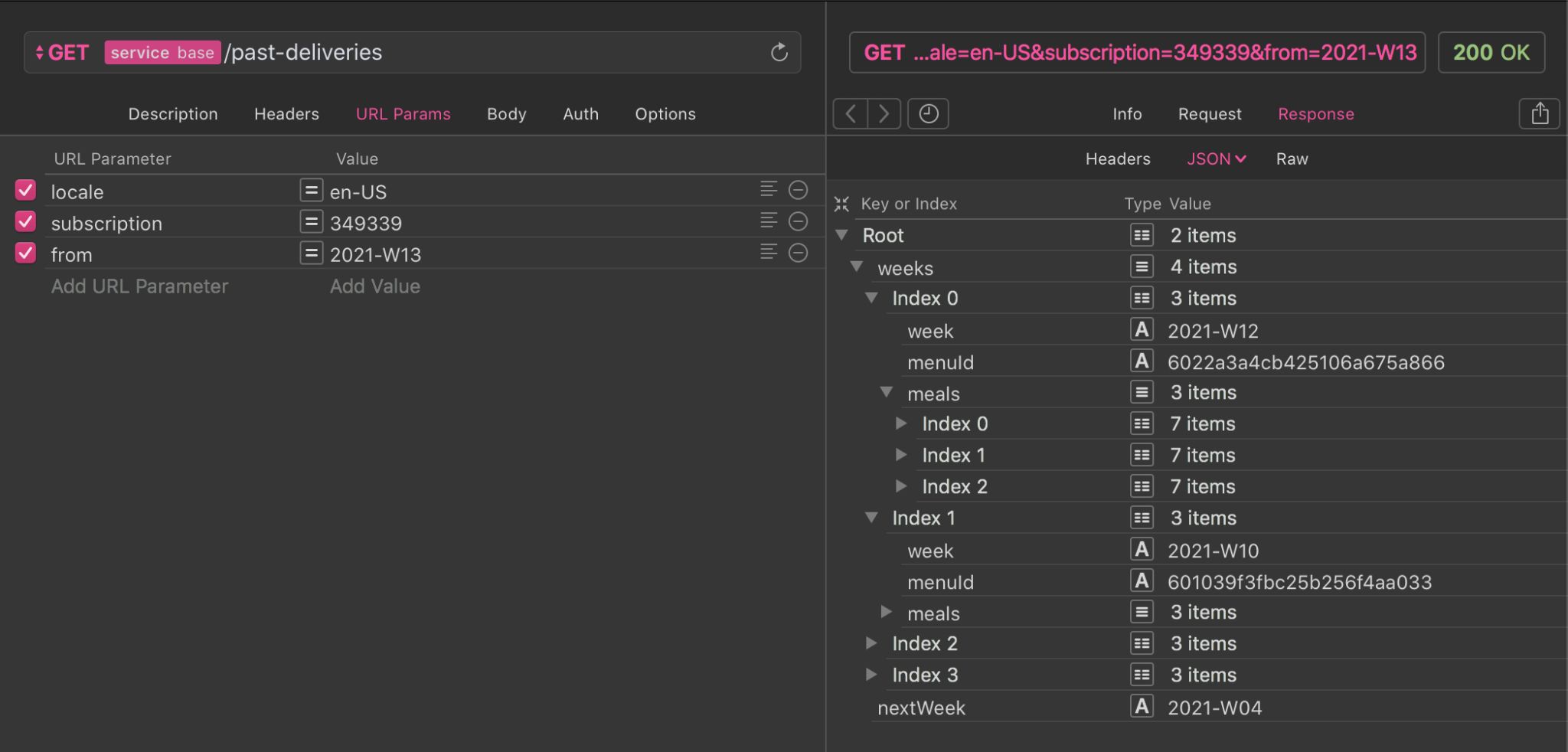
/past-deliveries endpointConclusion
To durably improve the user experience with My Deliveries, the most visited screen at HelloFresh, I started a multi-team, cross-functional endeavor to create a backend for frontend that would replace a slow and brittle monolith endpoint with a fast and reliable one. Along the way, we extracted features out of the monolith, improved our services, and even got inspired to launch spin-off projects. We adopted better practices, such as spec-first and load testing, and we improved our collaboration skills with proposals and progress reports.